What impacts the number and quality of HiFi reads that are generated?
The longer the polymerase read gets, more passes of the SMRTbell are produced and consequently more evidence is accumulated per molecule. This increase in evidence translates into higher consensus accuracy, as depicted in the following plot:
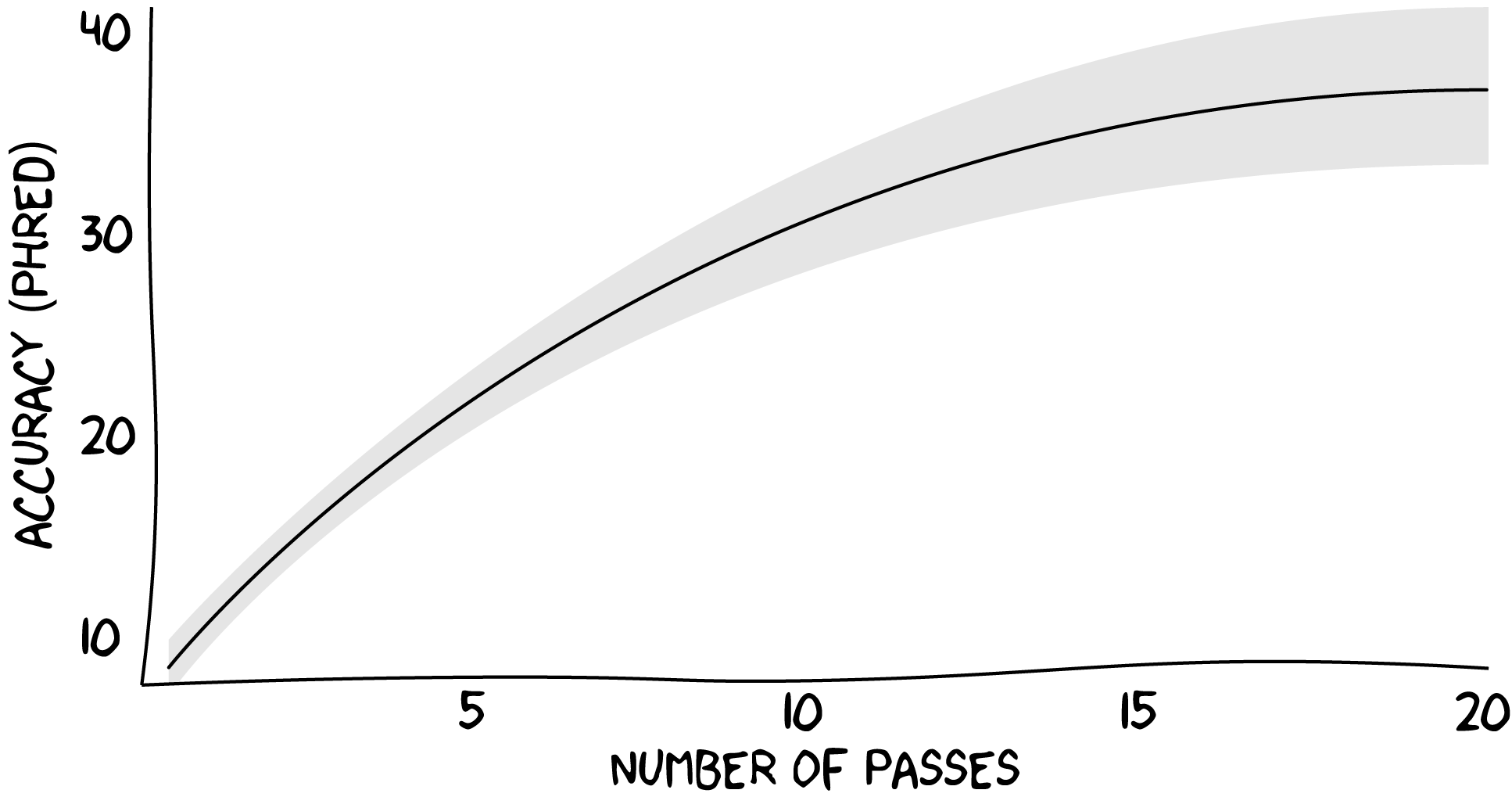
How is number of passes computed?
Each read is annotated with a np tag that contains the number of full-length subreads used for polishing. Full-length subreads are flanked by adapters and thus cover the full insert. Since the first version of ccs, number of passes has only accounted for full-length subreads. In version v3.3.0 windowing has been added, which takes the minimum number of full-length subreads across all windows. Starting with version v4.0.0, minimum has been replaced with mode to get a better representation across all windows. Only subreads that pass the subread length filter (please see next FAQ about filters) and were not dropped during polishing are counted.
Similarly, the tag ec reports effective coverage, the average subread coverage across all windows. This metric includes all subreads, independent of being full- or partial-length subreads, that pass length filters and did not fail during polishing. In most cases ec will be roughly np + 1.
Why do I get more yield if I increase --min-passes?
For versions newer than 3.0.0 and older than 4.2.0, we required that after draft generation, at least --min-passes subreads map back to the draft. Imagine the following scenario, a ZMW with 10 subreads generates a draft to which only a single subread aligns. This draft is of low quality and does not represent the ZMW, yet if you ask for --min-passes 1, this low-quality draft is being used. Starting with version 4.2.0, we switch to an additional percentage threshold of more than 50% aligning subreads to avoid this problem. This fixes the majority of discrepancies for fewer than three passes.
Why do we have this problem at all, shouldn’t the draft stage be robust enough? Robustness comes with inherent speed trade-offs. We have a cascade of different draft generators, from very fast and unstable to slow and robust. If a ZMW fails to generate a draft for a fast generator, it falls back multiple times until it reaches the slower and more robust generator. This approach is still much faster than always relying on the robust generator.
Is there an upper limit on number of passes used?
Per default, ccs uses at most the top 60 full-length passes after sorting by median length. Beyond this threshold, it has been shown that quality does not improve. You can change this limit with --top-passes, whereas 0 means unlimited.